Basics: Numerical Methods
Errors & Core Concepts
-
Significant Figures: Determine by all non-zero digits, zeros between them, and trailing zeros if a decimal point is present. Leading zeros are not significant.
-
Accuracy vs. Precision: Accuracy is closeness to the true value. Precision is closeness of multiple measurements to each other (reproducibility).
-
Error Definitions: Round-off (from finite computer precision), Truncation (from approximating a method, e.g., cutting a Taylor series), and Formulation (from an imperfect model).
-
Round-Off Errors: Occur because computers use a finite number of bits. Mitigate with higher precision (e.g., double) or by reordering calculations to avoid subtracting nearly equal numbers.
-
Truncation Errors & Taylor Series: The Taylor series represents a function as an infinite sum of its derivatives. Truncation error comes from cutting off (truncating) this series after a finite number of terms.
-
Error Propagation: Errors in initial values accumulate through calculations. Estimated using formulas based on partial derivatives (propagation of uncertainty).
-
Total Numerical Errors: Total Error Truncation Error + Round-off Error. These two are often a trade-off (e.g., smaller step size reduces truncation but increases round-off).
-
Formulation Errors: Errors from using a simplified or flawed mathematical model to represent a real-world problem (e.g., ignoring friction).
-
Data Uncertainty: Handled with statistical methods (like Monte Carlo analysis) or interval arithmetic. It reduces the confidence and accuracy of the solution.
-
Error Analysis: Assessing reliability by analyzing the method’s truncation error (e.g., its order ) and the potential for round-off error.
Here are additional viva questions and answers covering classification metrics.
Classification Metrics

-
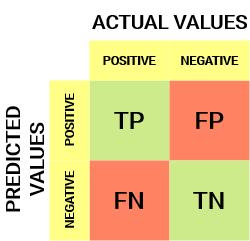
What is a confusion matrix?
A table that summarizes the performance of a classification model. It shows the counts of correct and incorrect predictions, broken down by their actual and predicted classes.
-
Define True Positive (TP).
TP: The model correctly predicted the positive class. (Actual: Positive, Predicted: Positive).
-
Define True Negative (TN).
TN: The model correctly predicted the negative class. (Actual: Negative, Predicted: Negative).
-
Define False Positive (FP). What type of error is this?
FP: The model incorrectly predicted the positive class when it was actually negative. (Actual: Negative, Predicted: Positive). This is a Type I Error.
-
Define False Negative (FN). What type of error is this?
FN: The model incorrectly predicted the negative class when it was actually positive. (Actual: Positive, Predicted: Negative). This is a Type II Error.
-
How do you calculate Accuracy?
Accuracy is the ratio of all correct predictions to the total number of predictions.
- Formula:
-
What is Precision? What is its formula?
Precision answers the question: “Of all the times the model predicted positive, how many were actually positive?” It measures a model’s “exactness.”
- Formula:
-
What is Recall (or Sensitivity)? What is its formula?
Recall answers the question: “Of all the actual positive cases, how many did the model correctly identify?” It measures a model’s “completeness.”
- Formula:
-
What is Specificity? What is its formula?
Specificity answers the question: “Of all the actual negative cases, how many did the model correctly identify?” It’s the “True Negative Rate.”
- Formula:
-
What is the F1-Score? Why is it useful?
The F1-Score is the harmonic mean of Precision and Recall. It’s useful because it provides a single score that balances both Precision and Recall, which is especially important for imbalanced datasets where accuracy can be misleading.
- Formula:
-
Give an example of a high-Precision, low-Recall scenario.
A very cautious spam filter. It only marks emails as spam if it’s 100% sure (High Precision), but it lets some obvious spam get into your inbox (Low Recall).
-
Give an example of a high-Recall, low-Precision scenario.
A medical screening test for a dangerous disease. It’s designed to catch everyone who might have the disease (High Recall), but it also flags many healthy people for further testing (Low Precision).
-
When would you prefer Precision over Recall?
When False Positives (Type I Error) are more costly than False Negatives.
- Example: Spam filtering. You would rather let some spam in (FN) than send an important email to the spam folder (FP).
-
When would you prefer Recall over Precision?
When False Negatives (Type II Error) are more costly than False Positives.
- Example: Cancer detection. You would rather tell a healthy person they might be sick (FP) than tell a sick person they are healthy (FN).
Root Finding
General
-
Transcendental equation? An equation containing non-algebraic functions (trigonometric, exponential, log). E.g., .
-
Algebraic vs. Transcendental? Algebraic equations involve only polynomial expressions (). Transcendental equations involve functions like , , .
-
Converge? The method’s approximations get closer and closer to the true root with each iteration.
-
Order of convergence? How fast the method converges. Higher order = faster convergence.
Iteration Method (Fixed-Point Iteration)
-
Principle? Rewrite as and iterate until converges.
-
Rewriting ? No, the form is not unique. (e.g., can be or ).
-
Condition for convergence? The absolute value of the derivative of , , must be less than 1 in the interval containing the root.
-
Order of convergence? Linear (Order 1).
Bisection Method
-
Principle? Repeatedly bisecting (halving) an interval and selecting the sub-interval in which the root must lie.
-
Condition? The function must be continuous, and the initial interval must satisfy (i.e., and have opposite signs).
-
Guaranteed to converge? Yes, always, if the initial conditions are met.
-
Order of convergence? Linear (Order 1). It’s slow because it halves the interval (error) at each step.
-
Iterations for accuracy ? .
False Position Method (Regula Falsi)
-
Improvement? It uses a secant line (a chord) to connect and instead of just taking the midpoint. The root approximation is where this line crosses the x-axis.
-
Formula? (or ).
-
Interval update? Same as bisection: keep the sub-interval where the sign of changes.
-
Convergence rate? Generally faster than bisection (superlinear).
-
Drawback? One of the interval endpoints can get “stuck,” leading to slow convergence in some cases (e.g., for convex functions).
Newton-Raphson Method
-
Geometric interpretation? Uses the tangent line to the curve at the current guess () to find the next guess () where the tangent hits the x-axis.
-
Iterative formula? . Derived from the first-order Taylor expansion.
-
Info needed? The function , its derivative , and an initial guess .
-
Order of convergence? Quadratic (Order 2), which is very fast.
-
Convergence conditions? The initial guess must be “sufficiently close” to the root, and near the root.
-
When does it fail? If (horizontal tangent), if the initial guess is poor (can diverge), or if it enters a loop.
Comparisons
-
Bisection vs. False Position: Bisection is guaranteed but slow. False Position is usually faster but can be slow if one endpoint gets stuck.
-
Bisection vs. N-R: Bisection is slow and reliable, only needs . N-R is very fast (quadratic) but requires and a good initial guess, and can fail.
-
Why N-R preferred? Its quadratic convergence (speed) is highly desirable, especially for complex problems where high precision is needed quickly.
Equation Solving
General
-
System of linear equations? A set of two or more linear equations with the same set of variables.
-
Direct vs. Iterative? Direct methods (like Gauss) find the exact solution in a finite number of steps (ignoring round-off error). Iterative methods start with a guess and refine it until it’s “close enough.”
-
Which methods? Cramer’s, Gauss Elimination, and Gauss-Jordan are direct methods.
-
Ill-conditioned system? A system where a small change in the coefficients or constant terms results in a large change in the solution.
Cramer’s Rule
-
Principle? Uses determinants to solve a system .
-
Finding ? , where is the matrix with its -th column replaced by the constant vector .
-
Disadvantage? Computationally very expensive (calculating many determinants) and inefficient for systems larger than 3x3.
-
When not applicable? If the determinant of the coefficient matrix is zero (), as this means the system has either no solution or infinitely many solutions.
Gauss Elimination Method
-
Two steps? 1. Forward Elimination (reducing to upper triangular form). 2. Back Substitution (solving for variables from bottom to top).
-
Forward elimination? Using elementary row operations to create zeros below the main diagonal, turning the matrix into an upper triangular form.
-
Back substitution? Solving the last equation (which has only one variable), then substituting that value into the second-to-last equation, and so on, moving up.
-
Pivoting? Swapping rows (partial pivoting) or rows and columns (full pivoting) to place the largest possible element in the pivot position. This is done to improve numerical stability and avoid division by zero or small numbers.
-
Zero pivot? If a zero appears on the diagonal and cannot be removed by row-swapping with a row below it, the system does not have a unique solution.
Gauss-Jordan Elimination
-
Difference? It continues the elimination process to create zeros above the main diagonal as well, resulting in a diagonal or identity matrix.
-
Final form? The augmented matrix is reduced to , where is the identity matrix and is the solution vector.
-
Advantage? It directly gives the solution vector; no back-substitution is needed.
-
Disadvantage? Requires more computations (approx. 50% more) than Gauss Elimination.
-
Finding inverse? Augment the matrix with the identity matrix and reduce to . The result will be .
Value Estimation (Interpolation)
General
-
Interpolation? Estimating the value of a function between known data points.
-
Interpolation vs. Extrapolation? Interpolation is estimating within the range of known data. Extrapolation is estimating outside that range (which is less reliable).
-
Interpolating polynomial? A polynomial that passes exactly through all the given data points.
-
Finite difference table? A table showing the differences between function values, and the differences of those differences, and so on.
Interpolation — Diagonal & Horizontal Differences
-
Forward difference ? .
-
Backward difference ? .
-
Central difference ? .
-
Forward difference table? A table listing , , , , etc. Used for Newton’s forward formula.
-
Newton’s Forward? When interpolating near the beginning of a set of equally spaced data points.
-
Newton’s Backward? When interpolating near the end of a set of equally spaced data points.
-
Limitation? The data points ( values) must be equally spaced.
Lagrange Interpolation Method
-
Advantage? It can be used when the data points ( values) are not equally spaced.
-
Form? A sum of terms: .
-
Basis polynomials ? is a polynomial designed to be 1 at and 0 at all other data points (where ).
-
Disadvantage? If a new data point is added, the entire polynomial must be recalculated from scratch.
Integration Approximation (Numerical Integration)
General
-
Why? To find the definite integral of a function that is too complex to integrate analytically (by hand) or when the function is only known as a set of data points.
-
Newton-Cotes? A family of formulas (like Trapezoidal, Simpson’s) that approximate the integral by fitting a polynomial to the data points and integrating that polynomial.
Trapezoidal Rule
-
Idea? Approximate the area under the curve using a trapezoid (i.e., approximating with a 1st-degree polynomial/straight line).
-
Single-application formula? , where .
-
Composite formula? .
-
Error order? Proportional to .
Simpson’s 1/3 Rule
-
Function? Approximates using a quadratic polynomial (a parabola).
-
Points/Intervals? Requires 3 points, which means 2 sub-intervals (or any even number of sub-intervals for composite).
-
Composite formula? .
-
Error order? Proportional to , which is much more accurate than Trapezoidal.
-
Condition on ? (the number of sub-intervals) must be even.
Simpson’s 3/8 Rule
-
Function? Approximates using a cubic polynomial.
-
Condition on ? (the number of sub-intervals) must be a multiple of 3.
-
When preferred? When is a multiple of 3, or sometimes used in combination with the 1/3 rule if is odd.
-
Accuracy? Also has an error order proportional to , but is generally slightly less accurate (larger error constant) than the 1/3 rule.
Ordinary Differential Equations (ODE)
General
-
Initial Value Problem (IVP)? An ODE where all required conditions (like ) are specified at the same, single starting value of .
-
Single-step vs. Multi-step? Single-step methods (like Euler, RK4) find using only information from the previous step . Multi-step methods (like Milne) use information from several previous steps ().
-
Which methods? Single-step: Euler’s, Picard’s, Runge-Kutta. Multi-step: Milne’s.
Euler’s Method
-
Interpretation? Takes the slope at the current point () and follows a straight line (the tangent) over a step to estimate the next point .
-
Formula? .
-
Error? Local error is (error per step). Global error is (total accumulated error).
-
Why inaccurate? It’s a first-order method and assumes the slope is constant over the whole step , which leads to large errors unless is extremely small.
Picard’s Method
-
What is it? An iterative method that solves the ODE by successively integrating it.
-
How? It turns the ODE into an integral equation and iterates: .
-
Drawback? The integration step can become very difficult or impossible to perform analytically after a few iterations.
Runge-Kutta (R-K) Methods
-
Purpose? To get higher accuracy (like a Taylor series) without needing to calculate higher derivatives of .
-
RK4? “4th order” means its global error is , which is very accurate.
-
Idea of RK4? It calculates a weighted average of four slopes at different points within the interval (at the
beginning, two in the middle, one at the end) to get a better estimate of the “true” slope over the interval.
-
Why popular? It’s a single-step method, easy to implement, self-starting, and provides a very good balance of accuracy and computational effort.
-
Single/Multi-step? It is a single-step method.
Milne’s Method (Milne-Simpson Predictor-Corrector)
-
Predictor-Corrector? A multi-step method that first “predicts” a value for (using an explicit formula) and then “corrects” that prediction (using an implicit formula) to get a more accurate value.
-
Formulas?
-
Predictor (Milne):
-
Corrector (Simpson):
-
-
Why multi-step? The formulas depend on values from previous steps ().
-
How to start? You need 4 starting points. These are usually generated using a single-step method like RK4.
-
Issue? Can suffer from numerical instability for certain types of ODEs.
Regression
General
-
Regression? A statistical method to find a function (model) that best fits a set of data points, used for predicting trends or values.
-
Interpolation vs. Regression? Interpolation must pass through all points. Regression finds a “best-fit” line/curve that minimizes the overall error and does not necessarily pass through any point.
-
Residual? The vertical distance between an actual data point () and the value predicted by the regression model (). Residual = .
Least Squares Regression
-
Principle? Find the parameters (coefficients) of the model that minimize the sum of the squares of the residuals.
-
Minimizing what? .
-
How to find parameters? Take the partial derivatives of the sum-of-squares error with respect to each parameter, set them to zero, and solve the resulting system of “normal equations.”
Linear Regression
-
Model? , where is the y-intercept and is the slope.
-
Normal equations? A 2x2 system for and :
-
-
? The “coefficient of determination.” It measures what proportion of the variance in the dependent variable () is predictable from the independent variable (). A value of 1.0 means a perfect fit.
Polynomial Regression
-
Model? (an -th degree polynomial).
-
Still “linear”? It’s “linear” because the model is linear in its coefficients (). We are still solving a linear system of normal equations for these coefficients.
-
Overfitting? Using too high of a polynomial degree, which makes the model fit the noise in the data perfectly but fail to generalize to new data. The curve will “wiggle” aggressively to hit all the points.
Logistic Regression
-
When used? For classification problems, where the output is a discrete category (e.g., Yes/No, 0/1, Spam/Not Spam), not a continuous value.
-
Sigmoid function? . It “squashes” any real-valued input into an output between 0 and 1, which can be interpreted as a probability.
-
What’s regressed? It finds a linear relationship for the log-odds (or “logit”) of the event: .
Stochastic Gradient Descent (SGD)
-
Gradient Descent? An iterative optimization algorithm used to find the minimum of a cost function (like the sum-of-squares error). It “descends” by taking steps in the direction of the steepest negative gradient.
-
Cost function? The function we want to minimize (e.g., Mean Squared Error in linear regression).
-
Batch vs. Stochastic?
-
Batch GD: Calculates the gradient using the entire dataset in one go to update the parameters.
-
Stochastic GD (SGD): Calculates the gradient and updates the parameters using only one data point (or a small “mini-batch”) at a time.
-
-
Epoch? One complete pass through the entire training dataset.
-
Learning rate? A hyperparameter () that controls how big of a step to take in the direction of the gradient.
-
Too large: Can overshoot the minimum and diverge.
-
Too small: Will take a very long time to converge.
-
-
Advantage of SGD? It’s much faster per-update and can escape local minima, making it ideal for very large datasets.